

先说结论
这次问题不是“Traefik 转发慢”,也不是单个请求路径的问题。
它更像一个控制面成本被放大的例子:Kubernetes 对象一变,Traefik 的 Kubernetes provider 收到 informer 事件,然后重新构建动态配置。单次 rebuild 看起来没什么,但当 EndpointSlice、Node 心跳、Gateway/Route 数量一起上来以后,就会变成很密的 CPU 尖刺。
我这次在本地 ~/code/traefik 的 fix/k8s-gateway-cpu-spikes 分支做了一组修复,commit 是:
53693e504 Reduce Kubernetes provider CPU churn主要改了四件事:
- 给 EndpointSlice informer 加
serviceNameindex,避免每次按 Service 找 EndpointSlice 都扫整个 namespace - 对 EndpointSlice update 做内容级过滤,只在 Traefik 真正消费的字段变化时触发 rebuild
- 对 Node update 做地址级过滤,忽略 kubelet 心跳带来的无关
Node.Status变化 - 在 Gateway provider 构建配置时给 listener 建索引,避免大量 Route 反复扫所有 Gateway listener
我的默认判断是:这类问题不要一上来就调大资源,也不要只靠 throttleDuration 压事件。先把复杂度和事件有效性搞清楚,收益更稳定。
问题从哪里来
背景是 Traefik 的这个 issue:
issue 里描述得比较完整:从 Traefik v3.0.4 升到 v3.1 以后,CPU 基线明显抬高,并且在 rollout、扩缩容、node autoscaler 活动时出现一串短促但很密的尖刺。作者后来 bisect 到一个很关键的变化:a8a92eb2a,也就是 v3.1.0 里迁移到 EndpointSlice API 的提交。
这里容易误判。
EndpointSlice 本身不是坏东西。Kubernetes 引入 EndpointSlice,本来就是为了解决传统 Endpoints 对象在大规模 Service 下不够可扩展的问题。它把一个 Service 后面的 endpoint 拆成多个 slice,这对 Kubernetes API 和 watch 传播是更好的。
但问题在于:数据模型变得更可扩展,不代表你的读取方式也自动变得更便宜。
如果 provider 每次加载一个 backend,都用 label selector 从 namespace 里列一遍 EndpointSlice,那么成本就从“按 Service 精确取”变成了“按 namespace 扫一遍再过滤”。当 Service、Route、Ingress path、EndpointSlice 数量叠起来以后,这个差异就会很明显。
issue 里给出的生产规模不是夸张的 hyperscale:
141 Ingresses 39 IngressRoutes343 Services342 EndpointSlices110 TraefikServices130 Middlewares这个规模我觉得很有代表性。它不是玩具集群,但也不是那种离普通团队很远的巨型集群。也正因为这样,这个问题值得修。
为什么它会变成 CPU 尖刺
我把这个问题拆成三条成本线看。
1. 每次 backend lookup 都扫 EndpointSlice
修复前的逻辑大概是这样:
c.factoriesKube[...]. Discovery(). V1(). EndpointSlices(). Lister(). EndpointSlices(namespace). List(serviceSelector)看起来是“按 Service 查 EndpointSlice”,但实际对 client-go 的 local cache 来说,这仍然是一次 selector list。也就是说,它要在 namespace 的 EndpointSlice 集合里做筛选。
如果一次配置构建里有很多 backend 引用,这个成本会被反复支付。
这类问题最麻烦的地方是,单独看一行代码不吓人,单次 list 也不一定慢。但放进 provider rebuild 的循环里,它会变成:
rebuild 次数 * route / ingress path 数量 * backend lookup 次数 * namespace 内 EndpointSlice 数量这就是控制面 CPU 问题常见的形状:不是某个函数慢到离谱,而是一个本来可以 O(1) 的查询,在热路径里退化成了 O(N)。
2. EndpointSlice 的无关 update 也触发完整 rebuild
Kubernetes informer 只要收到 update event,provider 就很容易进入“重新构建配置”的路径。
但 EndpointSlice 的 update 不一定都影响 Traefik 的路由结果。比如只改了 resourceVersion、managedFields,或者一些 Traefik 根本不消费的 metadata,重建配置就是浪费。
当然,这里不能粗暴忽略所有 condition-only update。
EndpointSlice 里的这些条件是有语义的:
ReadyServingTerminating
HTTP、TCP、UDP、Gateway provider 对这些字段的使用不完全一样。比如 endpoint 是否 ready,直接影响 server 是否应该进入配置。这里如果为了省 CPU 把 condition 变化吞掉,就会变成正确性问题。
所以正确做法不是“少看一点”,而是“只看真正参与配置语义的字段”。
3. Node 心跳把 provider 拖进 rebuild
还有一条很隐蔽的线是 Node informer。
当 Traefik 需要 cluster-scope 资源时,会 watch Node。Kubelet 会周期性更新 Node status,里面有 conditions、images、capacity、allocatable 等字段。对 Kubernetes 来说,这是正常心跳。
但 Traefik 在这里真正关心的通常只是 Node 地址,尤其是:
InternalIPExternalIP
如果 Node 的地址没变,只是心跳字段变了,就不应该触发一次完整的动态配置 rebuild。否则你就会得到一个很稳定的“无意义重建节拍”。
我这次具体怎么修
这次改动不大,但我刻意把它拆成几个很清楚的点。
EndpointSlice:给 informer cache 建索引
新增了一个 indexer:
const EndpointSliceServiceNameIndex = "endpointSliceServiceName"
var EndpointSliceServiceNameIndexers = cache.Indexers{ EndpointSliceServiceNameIndex: endpointSliceServiceNameIndexFunc,}
func EndpointSliceServiceNameIndexKey(namespace, serviceName string) string { return fmt.Sprintf("%s/%s", namespace, serviceName)}索引 key 是:
namespace/serviceName然后在各个 Kubernetes provider 的 EndpointSlice informer 上注册:
endpointSliceInformer := factoryKube.Discovery().V1().EndpointSlices().Informer()if err = endpointSliceInformer.AddIndexers(k8s.EndpointSliceServiceNameIndexers); err != nil { return nil, err}查询时不再 .List(selector),而是:
return k8s.EndpointSlicesByServiceName( informer.GetIndexer(), namespace, serviceName,)这块我没有只改 Gateway provider,而是一起覆盖了:
kubernetes/ingresskubernetes/crdkubernetes/gatewaykubernetes/ingress-nginx
原因很简单:这几个 provider 共享同一类 EndpointSlice lookup 成本。如果只修一个,问题还会在另一个入口形态里复现。
EndpointSlice event:比较值,不比较噪声
event_handler.go 里加了 EndpointSlice 的内容级判断。
核心思路是:
- service name label 变了,要 rebuild
- ports 变了,要 rebuild
- endpoint 地址变了,要 rebuild
- endpoint conditions 变了,要 rebuild
- 只有 metadata / resourceVersion / managedFields 这类变化,不 rebuild
这里有一个很小但很重要的细节:指针字段不能直接比指针地址。
EndpointSlice 的 port name、port、protocol,以及 endpoint conditions 里有不少 pointer 字段。两个对象的值一样,但指针地址不同,这是正常的。所以我加了一个泛型 helper:
func samePtr[T comparable](a, b *T) bool { if a == nil || b == nil { return a == b }
return *a == *b}这个点看起来很细,但在 informer update filter 里很容易踩坑。你以为自己在比较语义,实际上比较的是对象实例。
Node event:只看 Traefik 消费的地址
Node update 的过滤也类似。
Traefik 这里关心的是 InternalIP / ExternalIP,所以我把 Node 地址抽成 set:
func nodeAddressSet(addresses []corev1.NodeAddress) map[corev1.NodeAddress]struct{} { result := map[corev1.NodeAddress]struct{}{} for _, address := range addresses { if address.Type != corev1.NodeInternalIP && address.Type != corev1.NodeExternalIP { continue } result[address] = struct{}{} }
return result}这样 hostname 变化、capacity 变化、condition 心跳变化,都不会误触发 rebuild。只有真正影响 Traefik 入口地址判断的变化,才会继续往下走。
Gateway listener:不要每条 Route 都扫所有 listener
Gateway provider 里还有一个额外优化。
以前 HTTPRoute / GRPCRoute / TLSRoute / TCPRoute 匹配 Gateway listener 时,会拿 route 的 parentRefs 和所有 gateway listeners 做匹配。Route 数量一多,这也是典型的重复扫描。
我加了一个很小的 index:
type gatewayListenerIndex struct { byGateway map[ktypes.NamespacedName][]gatewayListener}构建配置时先把 listeners 按 namespace/name 分组。后面每条 Route 只需要根据 parentRef 找对应 Gateway 的 listeners。
这里不是为了炫技。它只是把数据结构调回正确形态:
大量 Route -> 少量 Gateway listener这种关系本来就应该用索引查,而不是每次全量扫。
修复后的结果
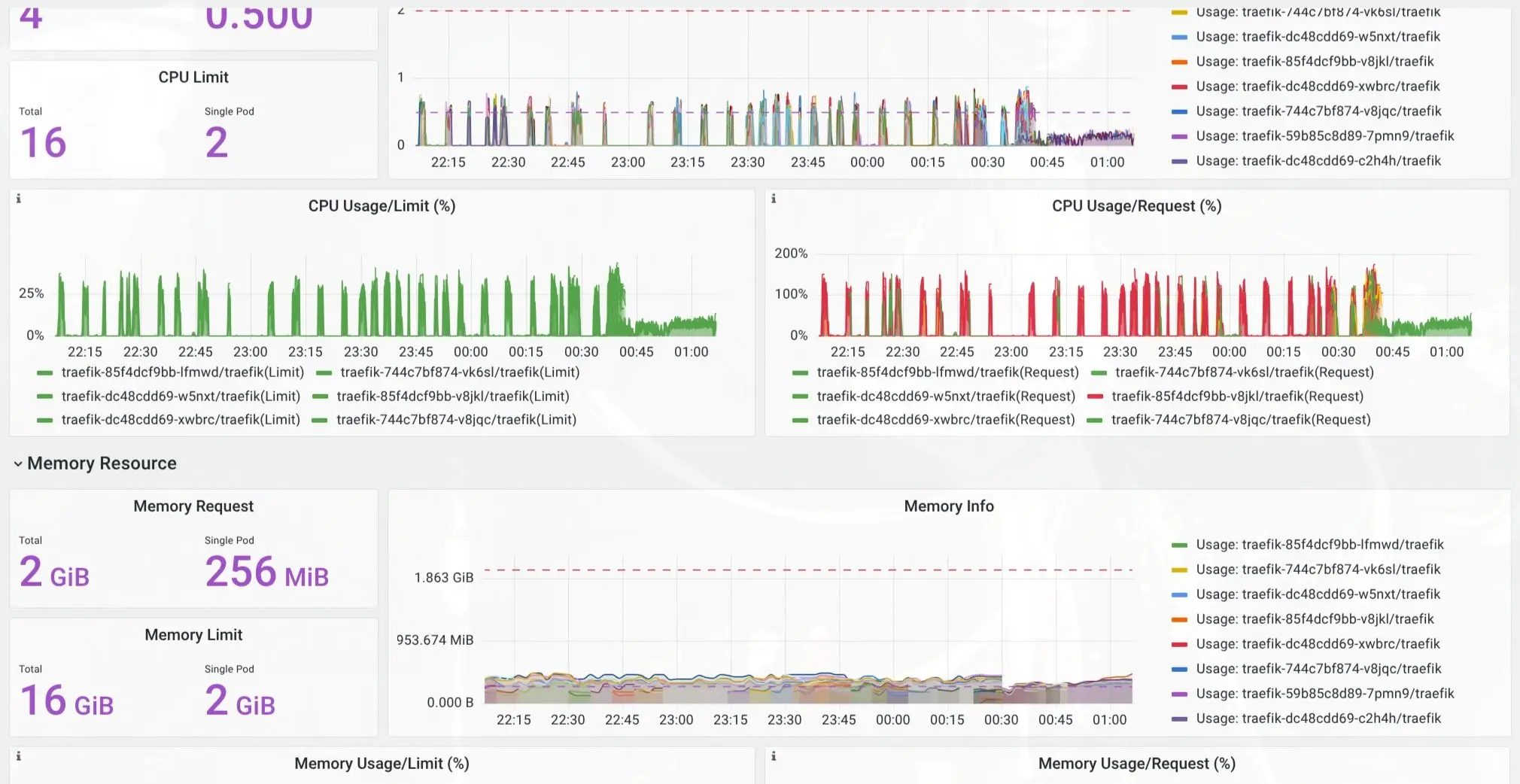
下面两张图是这次修复后的观测结果。
第一张图里可以看到,前半段有比较密集的 CPU 尖刺;修复生效后,CPU 使用明显收敛到低位,后面只剩很低的波动。
第二张图是修复后单独拉出来看,CPU 基本没有再出现之前那种密集尖刺。图里还有一些短小波峰,但它们已经不像之前那样持续把 Traefik provider 拖进高 CPU 区间。
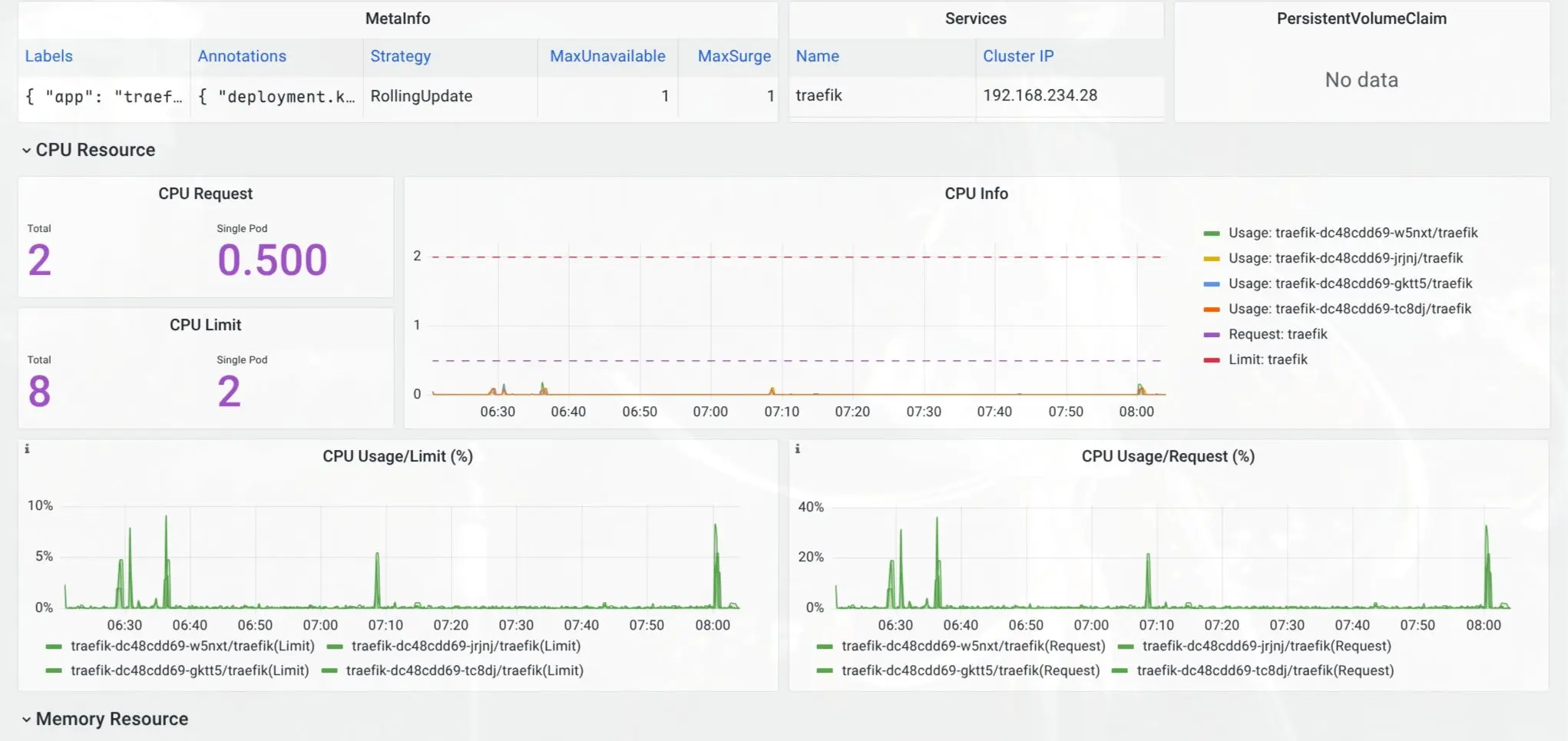
这里我不想把话说太满。
这两张图能说明的是:在这次测试环境里,修复后的 Traefik CPU 尖刺明显减少,稳定性更好。它不是一个严格 benchmark,也不能直接推导出所有集群都会下降多少百分比。
但从问题机制上看,这个结果是符合预期的:
- lookup 从 namespace scan 变成 index lookup
- 无关 EndpointSlice update 不再触发 rebuild
- Node heartbeat 不再周期性触发 rebuild
- Gateway Route 匹配 listener 的重复扫描减少
这些点加起来,CPU 曲线自然会从“频繁被事件打醒”变成“只有配置语义真的变化时才工作”。
我本地怎么验证
这次我至少跑了这两个包的测试:
go test ./pkg/provider/kubernetes/k8s ./pkg/provider/kubernetes/gateway结果是:
ok github.com/traefik/traefik/v3/pkg/provider/kubernetes/k8sok github.com/traefik/traefik/v3/pkg/provider/kubernetes/gateway新增测试主要覆盖三类行为:
EndpointSlicesByServiceName能按namespace/serviceName精确取到 EndpointSlice- EndpointSlice update filter 不会被无关 metadata 变化触发,但会保留 ports、addresses、conditions 的语义变化
- Node update filter 会忽略非地址字段变化,但 InternalIP / ExternalIP 变化仍然触发 rebuild
Gateway 侧还加了一个 benchmark,用来覆盖大量 Gateway listener 和 Route 场景下的匹配路径:
func BenchmarkGatewayListenerIndexMatching(b *testing.B)我比较在意的是测试边界,而不是只测 happy path。尤其是 condition 的 nil / true / false,这个地方如果测得不细,很容易为了性能把正确性修坏。
这类问题以后怎么查
如果以后我再遇到 Kubernetes controller / provider 的 CPU 抖动,我会优先按这个顺序查。
1. 先分清楚数据面和控制面
Traefik 的 CPU 高,不一定是请求转发高。
先看:
- 请求量有没有同步上升
- access log / metrics 里的 RPS 是否对应
- CPU 尖刺是否跟 rollout、scale、Node 事件、EndpointSlice 事件重合
- pprof 里热点是在转发路径,还是 provider rebuild 路径
如果热点在 provider,就不要先去调中间件、TLS、压缩这些数据面选项。
2. 看 informer event 是否真的有语义变化
很多控制器性能问题,本质是 event 太吵。
我会重点看这些对象:
- EndpointSlice
- Service
- Secret
- Ingress / HTTPRoute / Gateway
- Node
然后问一个问题:这个 update 真的会改变最终配置吗?
如果不会,就应该在 event handler 层过滤掉。靠后面的 hash、deep equal、throttle 都是补救,不是根治。
3. 看 hot path 里有没有 O(N) selector scan
client-go cache 不是数据库。
如果你在热路径里不断做 .List(selector),一定要问自己:
- selector 是否可以变成 indexer
- key 是否可以提前构造
- 是否可以在一次 rebuild 内做 per-service dedup
- 是否会随着 namespace 对象数量线性增长
EndpointSlice 这个问题就是很典型的例子。数据结构迁移本来是为了扩展性,但调用方如果还用 scan 的心智,扩展性收益会被吃掉。
4. 看 rebuild 有没有被重复触发
有些 rebuild 是必要的,比如 Route 变了、Service endpoint 变了、Secret 证书变了。
但有些 rebuild 只是噪声:
- Node heartbeat
- metadata managedFields 更新
- controller annotation tick
- resourceVersion 变化但 payload 不变
这些噪声如果不挡在入口,后面每一层都会付成本。
5. 最后再考虑 throttle
Traefik provider 本身有 throttle 相关配置,这类配置有用,但我不建议把它当第一优先级。
throttle 能把很多事件合并成更少的 rebuild,但它没有改变两件事:
- 单次 rebuild 本身还是贵
- 无意义事件仍然会进入系统
所以我的顺序会是:
- 先减少无意义事件
- 再降低单次 rebuild 成本
- 最后用 throttle 做工程上的缓冲
这次修复的边界
这次改动不是把所有 CPU 问题一次性解决。
issue 里还提到了一些后续方向,比如:
- annotation parse cache
- per-rebuild
loadService/loadServersdedup - 去掉 provider event loop 里冗余的 hash
- informer ingest 阶段 strip
managedFields
这些都还有继续优化空间。
但我觉得这次最值得先合的是前面三类:
- EndpointSlice indexer
- EndpointSlice event filter
- Node event filter
原因是它们分别对应三个不同成本轴:
| 修复点 | 解决的问题 | 风险 |
|---|---|---|
| EndpointSlice indexer | 单次 backend lookup 扫描太贵 | 低,语义不变 |
| EndpointSlice event filter | 无关 slice update 触发 rebuild | 中,需要保留 conditions 语义 |
| Node event filter | Node 心跳触发周期性 rebuild | 中,只能忽略 Traefik 不消费的字段 |
| Gateway listener index | 大量 Route 匹配 listener 重复扫描 | 低,数据结构优化 |
性能优化最怕的是“看起来快了,但语义被吞了”。所以这次我更倾向做保守修复:只优化明确浪费的路径,不碰 Gateway API 的行为语义。
结尾
这次修 Traefik,我最大的感受还是那句话:控制面性能问题,很多时候不是某个地方特别慢,而是很多“没必要做”的事情被高频做了。
EndpointSlice、Gateway API、informer cache 都是好东西。但它们放在一起以后,还是要回到很朴素的工程判断:
- 查找要不要建索引
- 事件有没有语义变化
- 热路径有没有重复扫描
- 正确性边界有没有被性能优化破坏
把这些问题问清楚,CPU 曲线自然会安静很多。